Kimi K2 Thinking
Новая модель и снова лидер
1. Знакомство с моделью
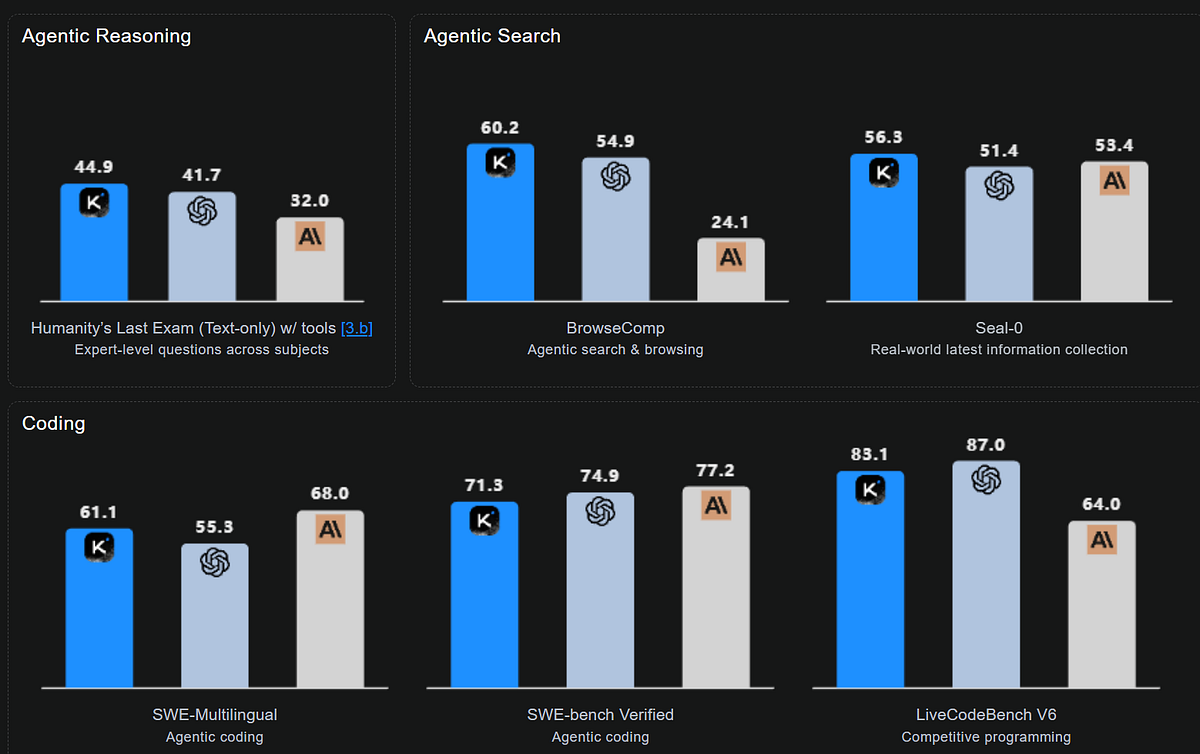
Kimi K2 Thinking — это новейшая и наиболее функциональная версия модели мышления с открытым исходным кодом. На основе Kimi K2 мы создали мыслящий агент, который рассуждает шаг за шагом, динамически вызывая инструменты. Он устанавливает новые стандарты в тестах Humanity's Last Exam (HLE), BrowseComp и других, значительно увеличивая глубину многоэтапных рассуждений и поддерживая стабильное использование инструментов в течение 200–300 последовательных вызовов. В то же время K2 Thinking — это собственная модель квантования INT4 с контекстным окном 256k, которая позволяет сократить задержку вывода и использование памяти графического процессора без потери качества.
Ключевые особенности
Глубокое мышление и управление инструментами: сквозное обучение, позволяющее чередовать цепочку логических рассуждений с вызовами функций, что обеспечивает автономные исследования, кодирование и написание текстов, состоящие из сотен шагов без отклонений.
Собственное квантование INT4: обучение с учётом квантования (QAT) применяется на этапе после обучения для достижения двукратного ускорения без потерь в режиме с низкой задержкой.
Стабильное долгосрочное агентство: сохраняет последовательное целенаправленное поведение при 200–300 последовательных вызовах инструмента, превосходя предыдущие модели, которые деградировали после 30–50 шагов.
2. Краткое описание модели
Архитектура Группа экспертов (ГЭ)
Общие Параметры 1Т
Активированные Параметры 32B
Количество слоёв (включая плотный слой) 61
Количество плотных слоёв 1
Внимание, Скрытое Измерение 7168
Скрытое измерение MoE (по мнению эксперта) 2048
Количество головок Внимания 64
Количество экспертов 384
Выбранные эксперты для каждого Токена 8
Количество общих экспертов 1
Размер Словарного запаса 160 ТЫСЯЧ
Длина контекста 256K
Механизм Привлечения внимания MLA
Функция активации СвиГЛУ
3. Результаты оценки
Логические задания
Эталонный показатель Настройка Мышление K2 GPT-5
(высокий уровень) Клод Сонет 4.5
(Размышления) K2 0905 DeepSeek-V3.2 Грок-4
HLE (только текст) никаких инструментов 23.9 26.3 19.8* 7.9 19.8 25.4
с инструментами 44.9 41.7 32.0 21.7 20.3* 41.0
тяжелый 51.0 42.0 - - - 50.7
ЦЕЛЬ25 никаких инструментов 94.5 94.6 87.0 51.0 89.3 91.7
ж / python 99.1 99.6 100.0 75.2 58.1* 98.8
тяжелый 100.0 100.0 - - - 100.0
HMMT25 никаких инструментов 89.4 93.3 74.6* 38.8 83.6 90.0
ж / python 95.1 96.7 88.8 70.4 49.5 93.9
тяжелый 97.5 100.0 - - - 96.7
IMO-верстак для ответов никаких инструментов 78.6 76.0 65.9 45.8 76.0* 73.1
GPQA никаких инструментов 84.5 85.7 83.4 74.2 79.9 87.5
Общие задачи
Эталонный показатель Настройка Мышление K2 GPT-5
(высокий уровень) Клод Сонет 4.5
(Размышления) K2 0905 DeepSeek-V3.2
MMLU-Pro никаких инструментов 84.6 87.1 87.5 81.9 85.0
MMLU-Redux никаких инструментов 94.4 95.3 95.6 92.7 93.7
Письмо в длинной форме никаких инструментов 73.8 71.4 79.8 62.8 72.5
Верстак здоровья никаких инструментов 58.0 67.2 44.2 43.8 46.9
Задачи Агентурного поиска
Эталонный показатель Настройка Мышление K2 GPT-5
(высокий уровень) Клод Сонет 4.5
(Размышления) K2 0905 DeepSeek-V3.2
BrowseComp с инструментами 60.2 54.9 24.1 7.4 40.1
BrowseComp-ZH с инструментами 62.3 63.0 42.4 22.2 47.9
Уплотнение-0 с инструментами 56.3 51.4 53.4 25.2 38.5*
FinSearchComp-T3 с инструментами 47.4 48.5 44.0 10.4 27.0*
Рамки с инструментами 87.0 86.0 85.0 58.1 80.2*
Задачи кодирования
Эталонный показатель Настройка Мышление K2 GPT-5
(высокий уровень) Клод Сонет 4.5
(Размышления) K2 0905 DeepSeek-V3.2
Проверенный SWE-стенд с инструментами 71.3 74.9 77.2 69.2 67.8
Многоязычный SWE-стенд с инструментами 61.1 55.3* 68.0 55.9 57.9
Многоступенчатая скамья с инструментами 41.9 39.3* 44.3 33.5 30.6
SciCode ( Код SciCode ) никаких инструментов 44.8 42.9 44.7 30.7 37.7
LiveCodeBenchV6 никаких инструментов 83.1 87.0 64.0 56.1* 74.1
OJ-Bench (cpp) никаких инструментов 48.7 56.2 30.4 25.5 38.2
Терминал-Стенд с использованием имитации инструментов (JSON) 47.1 43.8 51.0 44.5 37.7
Примечания
4. Собственное квантование INT4
Низкобитовое квантование — эффективный способ сократить время вывода и снизить нагрузку на память графического процессора на крупномасштабных серверах вывода. Однако в мыслительных моделях используется слишком большая длина декодирования, поэтому квантование часто приводит к значительному снижению производительности.
Чтобы решить эту проблему, на этапе после обучения мы используем обучение с учётом квантования (Quantization-Aware Training, QAT), применяя квантование только весов INT4 к компонентам MoE. Это позволяет K2 Thinking поддерживать собственный вывод INT4, увеличивая скорость генерации примерно в 2 раза и достигая при этом высочайшей производительности. Все результаты тестов приведены для точности INT4.
Контрольные точки сохраняются в формате сжатых тензоров, который поддерживается большинством основных механизмов логического вывода. Если вам нужны контрольные точки с более высокой точностью, например FP8 или BF16, вы можете обратиться к официальному репозиторию сжатых тензоров, чтобы распаковать веса int4 и преобразовать их в любую более высокую точность.
5. Развертывание
Вы можете получить доступ к API K2 Thinking на https://platform.moonshot.ai. Мы предоставляем API, совместимое с OpenAI/Anthropic.
В настоящее время Kimi-K2-Thinking рекомендуется использовать со следующими системами логического вывода:
vLLM
SGLang
KTransformers
Примеры развертывания можно найти в Руководстве по развертыванию моделей.